kubernetes会做系统中监控各个性能指标(比如节点cpu、内存、磁盘等),但是传统单机节点也需要从当初的catic、nagios、zabbix等转换到新的监控平台。这篇文章讲告诉大家如何通过容器化编排部署Prometheus+grafana+告警。
一.创建数据文件夹
mkdir -p /mnt/storage/prom/{prometheus,prometheus/data,alertmanager,grafana}
chmod 777 /mnt/storage/prom/{prometheus/data,grafana}
cd /mnt/storage/prom
二.创建配置文件
Prometheus
1.创建告警规则
vim /mnt/storage/prom/prometheus/alert-rules.yml
groups:
- name: node-alert
rules:
- alert: NodeDown
expr: up{job="node"} == 0
for: 1m
labels:
severity: critical
instance: "{{ $labels.instance }}"
annotations:
summary: "instance: {{ $labels.instance }} down"
description: "Instance: {{ $labels.instance }} 已经宕机 1分钟"
value: "{{ $value }}"
- alert: NodeCpuHigh
expr: (1 - avg by (instance) (irate(node_cpu_seconds_total{job="node",mode="idle"}[2m]))) * 100 > 85
for: 2m
labels:
severity: warning
instance: "{{ $labels.instance }}"
annotations:
summary: "instance: {{ $labels.instance }} cpu使用率过高"
description: "CPU 使用率超过 80%"
value: "{{ $value }}"
- alert: NodeCpuIowaitHigh
expr: avg by (instance) (irate(node_cpu_seconds_total{job="node",mode="iowait"}[2m])) * 100 > 80
for: 2m
labels:
severity: warning
instance: "{{ $labels.instance }}"
annotations:
summary: "instance: {{ $labels.instance }} cpu iowait 使用率过高"
description: "CPU iowait 使用率超过 50%"
value: "{{ $value }}"
- alert: NodeLoad5High
expr: node_load5 > (count by (instance) (node_cpu_seconds_total{job="node",mode='system'})) * 1.2
for: 2m
labels:
severity: warning
instance: "{{ $labels.instance }}"
annotations:
summary: "instance: {{ $labels.instance }} load(2m) 过高"
description: "Load(2m) 过高,超出cpu核数 1.2倍"
value: "{{ $value }}"
- alert: NodeMemoryHigh
expr: (1 - node_memory_MemAvailable_bytes{job="node"} / node_memory_MemTotal_bytes{job="node"}) * 100 > 90
for: 2m
labels:
severity: warning
instance: "{{ $labels.instance }}"
annotations:
summary: "instance: {{ $labels.instance }} memory 使用率过高"
description: "Memory 使用率超过 90%"
value: "{{ $value }}"
- alert: NodeDiskRootHigh
expr: (1 - node_filesystem_avail_bytes{job="node",fstype=~"ext.*|xfs",mountpoint ="/"} / node_filesystem_size_bytes{job="node",fstype=~"ext.*|xfs",mountpoint ="/"}) * 100 > 90
for: 10m
labels:
severity: warning
instance: "{{ $labels.instance }}"
annotations:
summary: "instance: {{ $labels.instance }} disk(/ 分区) 使用率过高"
description: "Disk(/ 分区) 使用率超过 90%"
value: "{{ $value }}"
- alert: NodeDiskBootHigh
expr: (1 - node_filesystem_avail_bytes{job="node",fstype=~"ext.*|xfs",mountpoint ="/boot"} / node_filesystem_size_bytes{job="node",fstype=~"ext.*|xfs",mountpoint ="/boot"}) * 100 > 80
for: 10m
labels:
severity: warning
instance: "{{ $labels.instance }}"
annotations:
summary: "instance: {{ $labels.instance }} disk(/boot 分区) 使用率过高"
description: "Disk(/boot 分区) 使用率超过 80%"
value: "{{ $value }}"
- alert: NodeDiskReadHigh
expr: irate(node_disk_read_bytes_total{job="node"}[2m]) > 20 * (1024 ^ 2)
for: 2m
labels:
severity: warning
instance: "{{ $labels.instance }}"
annotations:
summary: "instance: {{ $labels.instance }} disk 读取字节数 速率过高"
description: "Disk 读取字节数 速率超过 20 MB/s"
value: "{{ $value }}"
- alert: NodeDiskWriteHigh
expr: irate(node_disk_written_bytes_total{job="node"}[2m]) > 20 * (1024 ^ 2)
for: 2m
labels:
severity: warning
instance: "{{ $labels.instance }}"
annotations:
summary: "instance: {{ $labels.instance }} disk 写入字节数 速率过高"
description: "Disk 写入字节数 速率超过 20 MB/s"
value: "{{ $value }}"
- alert: NodeDiskReadRateCountHigh
expr: irate(node_disk_reads_completed_total{job="node"}[2m]) > 3000
for: 2m
labels:
severity: warning
instance: "{{ $labels.instance }}"
annotations:
summary: "instance: {{ $labels.instance }} disk iops 每秒读取速率过高"
description: "Disk iops 每秒读取速率超过 3000 iops"
value: "{{ $value }}"
- alert: NodeDiskWriteRateCountHigh
expr: irate(node_disk_writes_completed_total{job="node"}[2m]) > 3000
for: 2m
labels:
severity: warning
instance: "{{ $labels.instance }}"
annotations:
summary: "instance: {{ $labels.instance }} disk iops 每秒写入速率过高"
description: "Disk iops 每秒写入速率超过 3000 iops"
value: "{{ $value }}"
- alert: NodeInodeRootUsedPercentHigh
expr: (1 - node_filesystem_files_free{job="node",fstype=~"ext4|xfs",mountpoint="/"} / node_filesystem_files{job="node",fstype=~"ext4|xfs",mountpoint="/"}) * 100 > 80
for: 10m
labels:
severity: warning
instance: "{{ $labels.instance }}"
annotations:
summary: "instance: {{ $labels.instance }} disk(/ 分区) inode 使用率过高"
description: "Disk (/ 分区) inode 使用率超过 80%"
value: "{{ $value }}"
- alert: NodeInodeBootUsedPercentHigh
expr: (1 - node_filesystem_files_free{job="node",fstype=~"ext4|xfs",mountpoint="/boot"} / node_filesystem_files{job="node",fstype=~"ext4|xfs",mountpoint="/boot"}) * 100 > 80
for: 10m
labels:
severity: warning
instance: "{{ $labels.instance }}"
annotations:
summary: "instance: {{ $labels.instance }} disk(/boot 分区) inode 使用率过高"
description: "Disk (/boot 分区) inode 使用率超过 80%"
value: "{{ $value }}"
- alert: NodeFilefdAllocatedPercentHigh
expr: node_filefd_allocated{job="node"} / node_filefd_maximum{job="node"} * 100 > 80
for: 10m
labels:
severity: warning
instance: "{{ $labels.instance }}"
annotations:
summary: "instance: {{ $labels.instance }} filefd 打开百分比过高"
description: "Filefd 打开百分比 超过 80%"
value: "{{ $value }}"
- alert: NodeNetworkNetinBitRateHigh
expr: avg by (instance) (irate(node_network_receive_bytes_total{device=~"eth0|eth1|ens33|ens37"}[1m]) * 8) > 20 * (1024 ^ 2) * 8
for: 3m
labels:
severity: warning
instance: "{{ $labels.instance }}"
annotations:
summary: "instance: {{ $labels.instance }} network 接收比特数 速率过高"
description: "Network 接收比特数 速率超过 20MB/s"
value: "{{ $value }}"
- alert: NodeNetworkNetoutBitRateHigh
expr: avg by (instance) (irate(node_network_transmit_bytes_total{device=~"eth0|eth1|ens33|ens37"}[1m]) * 8) > 20 * (1024 ^ 2) * 8
for: 3m
labels:
severity: warning
instance: "{{ $labels.instance }}"
annotations:
summary: "instance: {{ $labels.instance }} network 发送比特数 速率过高"
description: "Network 发送比特数 速率超过 20MB/s"
value: "{{ $value }}"
- alert: NodeNetworkNetinPacketErrorRateHigh
expr: avg by (instance) (irate(node_network_receive_errs_total{device=~"eth0|eth1|ens33|ens37"}[1m])) > 15
for: 3m
labels:
severity: warning
instance: "{{ $labels.instance }}"
annotations:
summary: "instance: {{ $labels.instance }} 接收错误包 速率过高"
description: "Network 接收错误包 速率超过 15个/秒"
value: "{{ $value }}"
- alert: NodeNetworkNetoutPacketErrorRateHigh
expr: avg by (instance) (irate(node_network_transmit_packets_total{device=~"eth0|eth1|ens33|ens37"}[1m])) > 15
for: 3m
labels:
severity: warning
instance: "{{ $labels.instance }}"
annotations:
summary: "instance: {{ $labels.instance }} 发送错误包 速率过高"
description: "Network 发送错误包 速率超过 15个/秒"
value: "{{ $value }}"
- alert: NodeProcessBlockedHigh
expr: node_procs_blocked{job="node"} > 10
for: 10m
labels:
severity: warning
instance: "{{ $labels.instance }}"
annotations:
summary: "instance: {{ $labels.instance }} 当前被阻塞的任务的数量过多"
description: "Process 当前被阻塞的任务的数量超过 10个"
value: "{{ $value }}"
- alert: NodeTimeOffsetHigh
expr: abs(node_timex_offset_seconds{job="node"}) > 3 * 60
for: 2m
labels:
severity: info
instance: "{{ $labels.instance }}"
annotations:
summary: "instance: {{ $labels.instance }} 时间偏差过大"
description: "Time 节点的时间偏差超过 3m"
value: "{{ $value }}"
- alert: WindowsServerCollectorError
expr: windows_exporter_collector_success == 0
for: 0m
labels:
severity: critical
annotations:
summary: Windows Server collector Error (instance {{ $labels.instance }})
description: "Collector {{ $labels.collector }} was not successful\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: WindowsServerServiceStatus
expr: windows_service_status{status="ok"} != 1
for: 1m
labels:
severity: critical
annotations:
summary: Windows Server service Status (instance {{ $labels.instance }})
description: "Windows服务状态不正常\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: WindowsServerCpuUsage
expr: 100 - (avg by (instance) (rate(windows_cpu_time_total{mode="idle"}[2m])) * 100) > 80
for: 0m
labels:
severity: warning
annotations:
summary: Windows Server CPU Usage (instance {{ $labels.instance }})
description: "CPU使用率超过80%\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: WindowsServerMemoryUsage
expr: 100 - ((windows_os_physical_memory_free_bytes / windows_cs_physical_memory_bytes) * 100) > 90
for: 2m
labels:
severity: warning
annotations:
summary: Windows Server memory Usage (instance {{ $labels.instance }})
description: "内存使用率超过90%\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: WindowsServerDiskSpaceUsage
expr: 100.0 - 100 * ((windows_logical_disk_free_bytes / 1024 / 1024 ) / (windows_logical_disk_size_bytes / 1024 / 1024)) > 80
for: 2m
labels:
severity: critical
annotations:
summary: Windows Server disk Space Usage (instance {{ $labels.instance }})
description: "磁盘使用率超过80%\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
参考官网告警规则https://awesome-prometheus-alerts.grep.to/rules#windows-server 2.配置Prometheus与Alertmanager通信
vim /mnt/storage/prom/prometheus/prometheus.yml
global:
scrape_interval: 15s
evaluation_interval: 15s
alerting:
alertmanagers:
- static_configs:
- targets:
- alertmanager:9093
rule_files:
- "*rules.yml"
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['prometheus:9090']
- job_name: 'node'
static_configs:
- targets: ['node-exporter:9100']
- job_name: 'alertmanager'
static_configs:
- targets: ['alertmanager:9093']
3.热加载prometheus配置
curl -X POST http://localhost:9090/-/reload
确认加载完成

Alertmanager
上面配置了prometheus与alertmanager的通信,接下来我们配下alertmanager来实现发送告警信息给我们 这里我们主要以钉钉告警为例子
-
钉钉上添加一个钉钉机器人, 设置好名字,群组,选择加签,确定。
-
修改prometheus-webook配置文件绑定申请的机器人
vim /mnt/storage/prom/alertmanager/config.yml
templates:
- /etc/alertmanager/dingding.tmpl
targets:
webhook:
url: https://oapi.dingtalk.com/robot/send?access_token=xxxx #修改为钉钉机器人的webhook
secret: xxxx # 配置加签(申请的时候那串数字)
message:
title: '{{ template "ops.title" . }}' # 给这个webhook应用上 模板标题 (ops.title是我们模板文件中的title 可在下面给出的模板文件中看到)
text: '{{ template "ops.content" . }}'
mention:
all: true
vim /mnt/storage/prom/alertmanager/alertmanager.yml
global:
resolve_timeout: 5m
smtp_smarthost: 'smtp.qiye.163.com:465' #邮箱smtp服务器代理,启用SSL发信, 端口一般是465
smtp_from: 'user@163.com' #发送邮箱名称
smtp_auth_username: 'user@163.com' #邮箱名称
smtp_auth_password: 'password' #邮箱密码或授权码
smtp_require_tls: false
templates:
- '/etc/alertmanager/*.tmpl' #告警模板位置
route:
receiver: 'default' # 根据告警规则组名进行分组
group_wait: 10s # 分组内第一个告警等待时间,10s内如有第二个告警会合并一个告警
group_interval: 1m # 发送新告警间隔时间
repeat_interval: 1h #重复告警间隔发送时间,如果没处理过多久再次发送一次
group_by: ['alertname']
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'instance']
receivers:
- name: 'default'
email_configs:
- to: 'receiver@163.com'
send_resolved: true
headers: { Subject: " 【监控告警】 {{ .CommonLabels.alertname }} " } #标题
html: '{{ template "alertsList.html" . }}' #模板
webhook_configs:
- url: 'http://dingtalk:8060/dingtalk/webhook/send'
send_resolved: true # 在恢复后是否发送恢复消息给接收人
wechat_configs:
- send_resolved: true
message: '{{ template "wechat.default.message" . }}'
to_party: '2' # 企业微信中创建的接收告警的部门【告警机器人】的部门ID
agent_id: '100022222' # 企业微信中创建的应用的ID
message_type: markdown #改变格式
api_secret: 'awgJcJPA' # 企业微信中,应用的Secret
3.告警模板
vim ./dingding.tmpl ##钉钉
{{ define "__subject" }}
[{{ .Status | toUpper }}{{ if eq .Status "firing" }}:{{ .Alerts.Firing | len }}{{ end }}]
{{ end }}
{{ define "__alert_list" }}{{ range . }}
---
**告警类型**: {{ .Labels.alertname }}
**告警级别**: {{ .Labels.severity }}
**故障主机**: {{ .Labels.instance }}
**告警信息**: {{ .Annotations.description }}
**触发时间**: {{ (.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}
{{ end }}{{ end }}
{{ define "__resolved_list" }}{{ range . }}
---
**告警类型**: {{ .Labels.alertname }}
**告警级别**: {{ .Labels.severity }}
**故障主机**: {{ .Labels.instance }}
**触发时间**: {{ (.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}
**恢复时间**: {{ (.EndsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}
{{ end }}{{ end }}
{{ define "ops.title" }}
{{ template "__subject" . }}
{{ end }}
{{ define "ops.content" }}
{{ if gt (len .Alerts.Firing) 0 }}
**====侦测到{{ .Alerts.Firing | len }}个故障====**
{{ template "__alert_list" .Alerts.Firing }}
---
{{ end }}
{{ if gt (len .Alerts.Resolved) 0 }}
**====恢复{{ .Alerts.Resolved | len }}个故障====**
{{ template "__resolved_list" .Alerts.Resolved }}
{{ end }}
{{ end }}
{{ define "ops.link.title" }}{{ template "ops.title" . }}{{ end }}
{{ define "ops.link.content" }}{{ template "ops.content" . }}{{ end }}
{{ template "ops.title" . }}
{{ template "ops.content" . }}
vim ./email.tmpl ##邮件
{{ define "email.html" }}
{{- if gt (len .Alerts.Firing) 0 -}}
<h2>告警</h2>
<table border="5">
<tr><td>报警项</td>
<td>实例</td>
<td>报警详情</td>
<td>报警级别</td>
<td>开始时间</td>
</tr>
{{ range $i, $alert := .Alerts }}
<tr><td>{{ index $alert.Labels "alertname" }}</td>
<td style="color:#32CD32" >{{ index $alert.Labels "instance" }}</td>
<td>{{ index $alert.Annotations "description" }}</td>
<td>{{ $alert.Labels.severity }}</td>
<td style="color:#FF7F50">{{ $alert.StartsAt.Local.Format "2006-01-02 15:04:05" }}</td>
</tr>
{{ end }}
</table>
{{ end }}
{{- if gt (len .Alerts.Resolved) 0 -}}
<h2>已经恢复</h2>
<table border="5">
<tr><td>报警项</td>
<td>实例</td>
<td>报警详情</td>
<td>报警级别</td>
<td>开始时间</td>
<td>恢复时间</td>
</tr>
{{ range $i, $alert := .Alerts }}
<tr><td>{{ index $alert.Labels "alertname" }}</td>
<td style="color:#32CD32">{{ index $alert.Labels "instance" }}</td>
<td>{{ index $alert.Annotations "description" }}</td>
<td>{{ $alert.Labels.severity }}</td>
<td style="color:#FF7F50">{{ $alert.StartsAt.Local.Format "2006-01-02 15:04:05" }}</td>
<td style="color:#FF7F50">{{ $alert.EndsAt.Local.Format "2006-01-02 15:04:05" }}</td>
</tr>
{{ end }}
</table>
{{ end }}{{- end }}
vim ./wechat.tmpl ##企业微信
{{ define "wechat.message" }}
{{- if gt (len .Alerts.Firing) 0 -}}
{{- range $index, $alert := .Alerts -}}
{{- if eq $index 0 -}}
# 报警项: {{ $alert.Labels.alertname }}
{{- end }}
> `**===告警详情===**`
> 告警级别: {{ $alert.Labels.severity }}
> 告警详情: <font color="comment">{{ index $alert.Annotations "description" }}{{ $alert.Annotations.message }}</font>
> 故障时间: <font color="warning">{{ $alert.StartsAt.Local.Format "2006-01-02 15:04:05" }}</font>
> 故障实例: <font color="info">{{ $alert.Labels.instance }}</font>
{{- end }}
{{- end }}
{{- if gt (len .Alerts.Resolved) 0 -}}
{{- range $index, $alert := .Alerts -}}
{{- if eq $index 0 -}}
# 恢复项: {{ $alert.Labels.alertname }}
{{- end }}
> `**===恢复详情===**`
> 告警级别: {{ $alert.Labels.severity }}
> 告警详情: <font color="comment">{{ index $alert.Annotations "description" }}{{ $alert.Annotations.message }}</font>
> 故障时间: <font color="warning">{{ $alert.StartsAt.Local.Format "2006-01-02 15:04:05" }}</font>
> 恢复时间: <font color="warning">{{ $alert.EndsAt.Local.Format "2006-01-02 15:04:05" }}</font>
> 故障实例: <font color="info">{{ $alert.Labels.instance }}</font>
{{- end }}
{{- end }}
{{- end }}
三.创建docker-compose.yaml
vim /mnt/storage/prom/docker-compose.yml
version: '3.7'
services:
node-exporter:
image: prom/node-exporter:latest
ports:
- "9100:9100"
networks:
- prom
dingtalk:
image: timonwong/prometheus-webhook-dingtalk:latest
volumes:
- type: bind
source: ./alertmanager/config.yml
target: /etc/prometheus-webhook-dingtalk/config.yml
read_only: true
- type: bind
source: ./alertmanager/dingding.tmpl
target: /etc/alertmanager/dingding.tmpl
read_only: true
ports:
- "8060:8060"
networks:
- prom
alertmanager:
depends_on:
- dingtalk
image: prom/alertmanager:latest
volumes:
- type: bind
source: ./alertmanager/alertmanager.yml
target: /etc/alertmanager/alertmanager.yml
read_only: true
- type: bind
source: ./alertmanager/dingding.tmpl
target: /etc/alertmanager/dingding.tmpl
read_only: true
- type: bind
source: ./alertmanager/email.tmpl
target: /etc/alertmanager/email.tmpl
read_only: true
- type: bind
source: ./alertmanager/wechat.tmpl
target: /etc/alertmanager/wechat.tmpl
read_only: true
ports:
- "9093:9093"
- "9094:9094"
networks:
- prom
prometheus:
depends_on:
- alertmanager
image: prom/prometheus:latest
volumes:
- type: bind
source: ./prometheus/prometheus.yml
target: /etc/prometheus/prometheus.yml
read_only: true
- type: bind
source: ./prometheus/alert-rules.yml
target: /etc/prometheus/alert-rules.yml
read_only: true
- type: volume
source: prometheus
target: /prometheus
ports:
- "9090:9090"
networks:
- prom
grafana:
depends_on:
- prometheus
image: grafana/grafana:latest
volumes:
- type: volume
source: grafana
target: /var/lib/grafana
ports:
- "3000:3000"
networks:
- prom
volumes:
prometheus:
driver: local
driver_opts:
type: none
o: bind
device: /Users/sk/Desktop/k3s/prometheus/prom/prometheus/data
grafana:
driver: local
driver_opts:
type: none
o: bind
device: /Users/sk/Desktop/k3s/prometheus/prom/grafana
networks:
prom:
driver: bridge
启动配置granafa 模板8919 16098 https://grafana.com/grafana/dashboards/16098-1-node-exporter-for-prometheus-dashboard-cn-0417-job/
四.服务端
1.安装软件
tar -xf node_exporter-1.0.0-rc.0.linux-amd64.tar.gz
ls
mv node_exporter-1.0.0-rc.0.linux-amd64 /usr/local/node_exporter
ls /usr/local/node_exporter
2.编写服务service文件
vim /usr/lib/systemd/system/node_exporter.service
[Unit]
Description=node_exporter
After=network.target
[Service]
Type=simple
ExecStart=/usr/local/node_exporter/node_exporter
[Install]
WantedBy=multi-user.target
systemctl enable node_exporter –now
--------------------------------------------------------
#配置开机自启
vim /etc/rc.local
/usr/wubin/node_exporter1.1/node_exporter &
3.设置防火墙、SELinux
firewall-cmd --set-default-zone=trusted
setenforce 0
sed -i '/SELINUX/s/enforcing/permissive/' /etc/selinux/config
五.测试
1.我们可以通过故意调整阈值 或者 停掉告警检测中主机上的node_exporter探针来测试一下
systemctl stop node_exporter.service
2.prometheus上可以看到已经触发了告警规则阈值
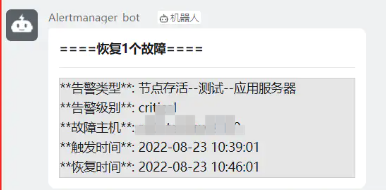
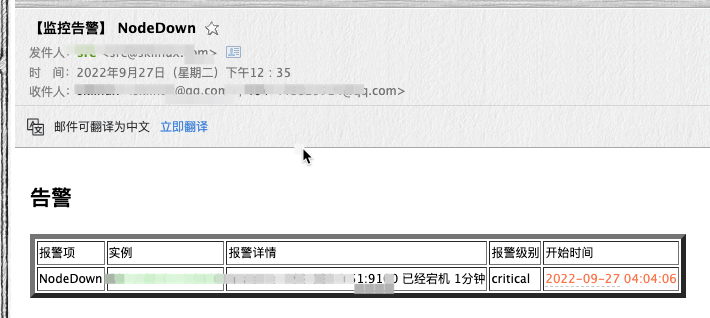
 3.此时钉钉群和邮箱里收到了告警邮件
3.此时钉钉群和邮箱里收到了告警邮件

 4.其他测试
CPU
4.其他测试
CPU
stress --cpu 4
# 4个CPU核心设置满载状态
内存
# 表示运行3个进程,每个进程分配500M内存
stress --vm 3 --vm-bytes 500M --vm-keep
内存
# github地址
https://github.com/woodcutter-wg/agp